Crawling in SEO refers to the process by which search engine bots (also known as spiders or crawlers) systematically browse the web to discover and index content. These bots follow links from one webpage to another, building a map of the internet’s content. Here’s a comprehensive look at what crawling involves and why it’s important for SEO:
How Crawling Works
- Initiation:
- Seed URLs: Crawlers start with a list of seed URLs provided by the search engine. These are usually well-known, high-authority sites.
- Recurrence: Crawlers regularly revisit websites to check for updates or new content.
- Following Links:
- Link Traversal: Crawlers follow hyperlinks on the pages they visit to discover new URLs. This includes internal links (within the same site) and external links (to other sites).
- Breadth-First vs. Depth-First: Crawlers may use different strategies, such as breadth-first (exploring all links on a page before moving deeper) or depth-first (following one path as deep as possible before backtracking).
- Fetching Content:
- HTTP Requests: Crawlers make HTTP requests to fetch the content of the pages. They read the HTML, JavaScript, CSS, and other elements to understand the structure and content.
- Resource Management: Crawlers manage their resources to avoid overloading websites with too many requests in a short period.
- Parsing and Indexing:
- Content Analysis: Once the content is fetched, the crawler parses the HTML to extract meaningful information, such as text content, meta tags, and structured data.
- Indexing: Relevant content is then indexed, meaning it is added to the search engine’s database. This indexed content is what gets displayed in search results when users enter queries.
Importance of Crawling for SEO
- Discoverability:
- Visibility: For your website to appear in search engine results, its pages need to be discovered and indexed by crawlers. Without crawling, a page cannot be indexed, and therefore, it won’t show up in search results.
- Freshness:
- Content Updates: Regular crawling ensures that new content, updates, and changes to existing content are discovered and reflected in search engine indices. This helps in keeping search results relevant and up-to-date.
- SEO Strategy Implementation:
- Optimization: Crawlers identify how well your site adheres to SEO best practices, such as proper use of keywords, meta tags, and structured data. They also detect technical issues that may impact SEO, such as broken links and duplicate content.
Factors Influencing Crawling
- Crawl Budget:
- Definition: The crawl budget is the number of pages a search engine bot will crawl on your site within a given time frame. It is influenced by the site’s size, the number of new pages, and the server’s capacity.
- Optimization: Efficient site architecture, clean URLs, and avoiding duplicate content can help optimize your crawl budget.
- Robots.txt File:
- Directive File: This file gives instructions to search engine bots about which pages or sections of the site they are allowed to crawl and index.
- Syntax: Correctly configuring the robots.txt file ensures that only the relevant parts of your site are crawled and prevents overloading the server with unnecessary crawl requests.
- Sitemaps:
- XML Sitemaps: These files provide a roadmap of your site’s important pages. Submitting a sitemap helps search engines discover new and updated content quickly.
- Priority and Frequency: Sitemaps can also include metadata about the frequency of updates and the priority of pages, guiding crawlers on how often to revisit pages.
- Internal Linking:
- Link Structure: Effective internal linking helps crawlers navigate and discover all important pages within your site. A well-structured internal link hierarchy ensures deeper pages get crawled and indexed.
- Anchor Text: Relevant anchor text in internal links helps search engines understand the context and importance of linked pages.
- Site Speed and Performance:
- Loading Time: Faster-loading sites tend to be crawled more efficiently. If a site loads slowly, crawlers may not be able to fetch all the pages within the allocated crawl budget.
- Error Pages: Minimizing server errors (such as 5xx errors) and broken links (404 errors) helps maintain a smooth crawling process.
Conclusion
Crawling is a fundamental process in SEO that enables search engines to discover and index web content. By understanding how crawling works and the factors that influence it, website owners and SEO professionals can optimize their sites to ensure better discoverability, faster indexing of new content, and overall improved search engine performance. Regularly updating sitemaps, optimizing crawl budget, and maintaining a clean, efficient site structure are key practices to facilitate effective crawling.
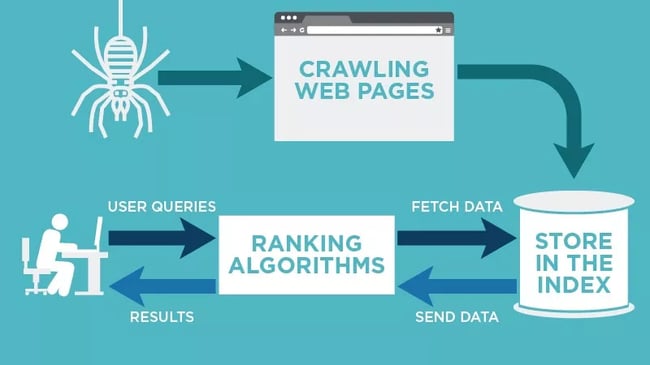
How Does Crawling Work?
Crawling is a fundamental process used by search engines to discover and index new and updated web content. Here’s a detailed look at how crawling works:
1. Starting with Seed URLs
Search engines begin the crawling process with a set of initial URLs known as seed URLs. These are typically high-authority websites or pages that are already well-known to the search engine.
2. Fetching the Content
- HTTP Requests: The crawler sends an HTTP request to the server hosting the webpage. This request retrieves the HTML content of the page, along with other resources such as CSS, JavaScript, and images.
- Parsing HTML: The crawler parses the HTML content to understand the structure of the webpage, including the text, metadata, and links.
3. Following Links
- Internal Links: Crawlers follow internal links to discover other pages within the same website. Effective internal linking helps ensure that all important pages are discovered and indexed.
- External Links: Crawlers also follow external links to discover new websites and content. This helps expand the crawler’s reach across the web.
4. Handling Directives
- robots.txt File: Before crawling a site, crawlers check the
robots.txtfile to see which parts of the site they are allowed to access. This file provides rules about which pages should not be crawled. - Meta Robots Tags: Individual pages can use meta robots tags to provide additional instructions to crawlers, such as “noindex” to prevent a page from being indexed or “nofollow” to prevent following links on that page.
5. Managing Crawl Budget
- Crawl Rate: The frequency and number of requests a crawler makes to a website is managed to avoid overloading the server. This is influenced by the website’s size, its update frequency, and the server’s capacity to handle requests.
- Crawl Demand: Search engines prioritize crawling pages that are more likely to be updated frequently or are deemed more important based on various signals, such as user behavior and link popularity.
6. Extracting and Storing Data
- Content Extraction: The crawler extracts and analyzes the page content, including text, images, and metadata. This information is stored in the search engine’s index.
- Link Extraction: All the links found on the page are extracted and added to the list of URLs to be crawled next. This ensures continuous discovery of new pages and updates to existing ones.
7. Handling JavaScript and Dynamic Content
- Rendering: Modern crawlers are capable of rendering JavaScript and dynamic content. This allows them to index content that is loaded dynamically by JavaScript, which is increasingly common in modern web development.
- Single Page Applications (SPAs): Crawlers can handle SPAs by executing JavaScript to load different views and content, ensuring that all the content is indexed correctly.
8. Error Handling and Reporting
- Error Pages: Crawlers encounter and report various errors such as 404 (Not Found) or 500 (Server Error). These errors are recorded and can impact the overall health and indexing status of a site.
- Redirections: Proper handling of redirects (301, 302) ensures that the correct content is indexed and link equity is preserved.
9. Regular Recrawling
- Frequency: Crawlers regularly revisit websites to check for updates or new content. The frequency of recrawling depends on the site’s update rate, its importance, and the historical changes noted by the crawler.
- Change Detection: When a page is updated, the new content is indexed, and the previous version is replaced. This keeps the search engine’s index current and relevant.
10. Specialized Crawlers
- Mobile Crawlers: Search engines use mobile-specific crawlers to understand and index content as it appears on mobile devices. This is crucial for mobile-first indexing.
- Image and Video Crawlers: Specialized crawlers index multimedia content, extracting metadata and ensuring it appears in relevant search results.
Conclusion
Crawling is a sophisticated process that involves discovering new and updated content, following links, respecting directives, managing resources, and handling errors. By understanding how crawling works, website owners can optimize their sites to be more crawler-friendly, ensuring better discoverability and higher chances of being indexed accurately and promptly by search engines.