Web crawling tools, also known as web scrapers or spiders, are software applications designed to systematically browse the web to extract and index data from websites.
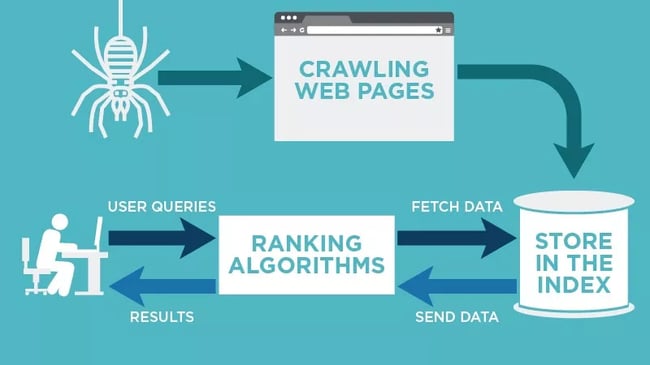
These tools are essential for various purposes such as search engine optimization (SEO), data mining, and web indexing. Here are some types of web crawling tools, categorized by their primary use cases and features:
1. Search Engine Crawlers
These are specialized crawlers used by search engines like Google, Bing, and Yahoo to index web pages and provide relevant search results.
- Googlebot: The main crawler used by Google to index web content.
- Bingbot: Used by Bing for the same purpose.
- Yandex Bot: The web crawler for the Russian search engine Yandex.
2. SEO Crawlers
SEO crawlers are designed to help website owners and SEO professionals analyze and optimize their sites for better search engine rankings.
- Screaming Frog SEO Spider: A popular desktop program that crawls websites’ links, images, scripts, and more to evaluate SEO performance.
- Sitebulb: Offers visual audits and insights into website structure and technical SEO issues.
- DeepCrawl: A cloud-based crawler that provides comprehensive SEO analysis and reporting.
3. General-Purpose Web Crawlers
These crawlers are used for a wide range of data extraction tasks, from scraping content to monitoring website changes.
- Octoparse: A user-friendly tool that allows you to scrape web data without coding.
- ParseHub: A visual data extraction tool that handles dynamic and interactive web content.
- WebHarvy: A point-and-click web scraping software that automatically identifies patterns on web pages.
4. E-commerce Crawlers
Specialized for scraping product data, prices, and reviews from e-commerce websites.
- Price2Spy: A tool for monitoring competitor prices, price changes, and market trends.
- Helium 10: An all-in-one software suite for Amazon sellers, including a crawler for product and keyword research.
- Import.io: Extracts data from e-commerce sites to gather competitive intelligence and market insights.
5. Academic and Research Crawlers
Used by researchers to gather data for academic studies and large-scale data analysis.
- WebDataRocks: A tool for researchers to collect and analyze data from various websites.
- Scrapy: An open-source web crawling framework in Python, widely used for academic purposes due to its flexibility and power.
- Diffbot: An AI-driven web extraction tool used in academic research to structure web data.
6. Social Media Crawlers
Focused on extracting data from social media platforms to analyze trends, user behavior, and content performance.
- Netlytic: A cloud-based text and social networks analyzer for collecting and analyzing social media data.
- ScrapeStorm: Supports scraping data from social media sites like Twitter and Facebook.
- Phantombuster: Automates data extraction from various social media platforms, including LinkedIn, Twitter, and Instagram.
7. Customizable and Programmable Crawlers
These tools are designed for developers who need advanced customization and control over their crawling processes.
- Beautiful Soup: A Python library for web scraping that allows developers to extract data from HTML and XML files.
- Puppeteer: A Node.js library providing a high-level API to control headless Chrome or Chromium, useful for scraping dynamic websites.
- Cheerio: A fast, flexible, and lean implementation of jQuery designed specifically for server-side web scraping in Node.js.
8. Enterprise-Level Crawlers
Designed for large organizations needing robust, scalable, and comprehensive data extraction solutions.
- ContentKing: Continuously monitors websites for changes and issues, ensuring SEO best practices are maintained.
- OnCrawl: An SEO crawler and log analyzer for enterprise-level websites, offering deep insights and advanced reporting.
- BrightEdge: An enterprise SEO platform that includes a powerful web crawler for monitoring and optimizing search performance.
Conclusion
Choosing the right web crawling tool depends on your specific needs, whether it’s for SEO, e-commerce, academic research, or general data extraction. Tools like Screaming Frog and DeepCrawl are excellent for SEO analysis, while Octoparse and ParseHub are great for general-purpose scraping. For developers, frameworks like Scrapy and libraries like Beautiful Soup offer the flexibility needed for customized crawling tasks. Understanding the capabilities and limitations of each type of crawler will help you select the best tool for your requirements.